
Grey-box Extraction of Natural Language Models
International Conference on Machine Learning |
Published by PMLR
Editor(s): Marina Meila and Tong Zhang
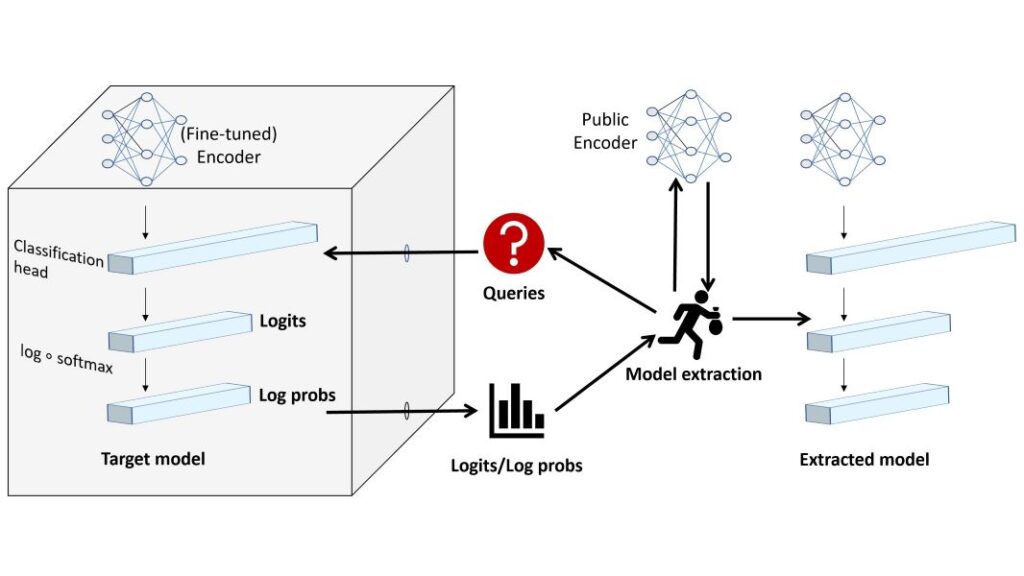
Model extraction attacks attempt to replicate a target machine learning model by querying its inference API. State-of-the-art attacks are learning based and construct replicas by supervised training on the target model’s predictions, but an emerging class of attacks exploit algebraic properties to obtain high-fidelity replicas using orders of magnitude fewer queries. So far, these algebraic attacks have been limited to neural networks with few hidden layers and ReLU activations. In this paper we present algebraic and hybrid algebraic/learning-based attacks on large-scale natural language models. We consider a grey-box setting, targeting models with a pre-trained (public) encoder followed by a single (private) classification layer. Our key findings are that (i) with a frozen encoder, high-fidelity extraction is possible with a small number of in-distribution queries, making extraction attacks indistinguishable from legitimate use; (ii) when the encoder is fine-tuned, a hybrid learning-based/algebraic attack improves over the learning-based state-of-the-art without requiring additional queries.
Proceedings of the 38th International Conference on Machine Learning, PMLR 139, 2021. Copyright 2021 by the author(s). Licensed under CC BY-SA 4.0.