
Multi-View Learning for Speech Emotion Recognition
- Daniel Tompkins ,
- Dimitra Emmanouilidou ,
- Soham Deshmukh ,
- Benjamin Elizalde
International Conference on Acoustics, Speech and Signal Processing |
Published by IEEE
Psychological research has postulated that emotions and sentiment are correlated to dimensional scores of valence, arousal, and dominance. However, the literature of Speech Emotion Recognition focuses on independently predicting
the three of them for a given speech audio. In this paper, we evaluate and quantify the predictive power of the dimensional scores towards categorical emotions and sentiment for two publicly available speech emotion datasets. We utilize the three emotional views in a joined multi-view training framework. The views comprise the dimensional scores, emotions categories, and sentiment categories. We present a comparison for each emotional view or combination of, utilizing two general-purpose models for speech-related applications: CNN14 and Wav2Vec2. To our knowledge this is the first time such a joint framework is explored. We found that a joined multi-view training framework can produce results as strong or stronger than models trained independently for each view.

The outer circle and emotions are the circumplex model of affect, adapted from Posner et al., 2005. The x-axis represents valence while the y-axis represents arousal. We plotted inside the circle the mean valence and arousal values and their standard deviations of 8 emotions from the MSP-Podcast dataset.
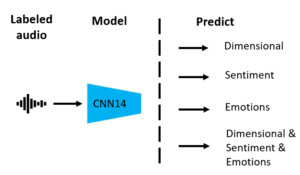 Multi-view framework for prediction of Dimensional scores, Sentiment Categories, and Emotion Categories. The output layer varies per model: three regression outputs for three Dimensional classes (valence, arousal and dominance); three classes for sentiment (Pos, Neu, Neg); five classes for Emotions; and the combinations (Dimensional + Sentiment, Dimensional + Emotion, or all 3).
Multi-view framework for prediction of Dimensional scores, Sentiment Categories, and Emotion Categories. The output layer varies per model: three regression outputs for three Dimensional classes (valence, arousal and dominance); three classes for sentiment (Pos, Neu, Neg); five classes for Emotions; and the combinations (Dimensional + Sentiment, Dimensional + Emotion, or all 3).