

This content has been archived, and while it was correct at time of publication, it may no longer be accurate or reflect the current situation at Microsoft.
System crashes and other failures have long been a fact of life in the IT world.
Microsoft has always worked hard to ensure that its customers have reliable software tools, but it experiences problems as well. To reduce the severity and length of system failures, Microsoft Digital core—the engineering organization at Microsoft that builds and manages the products, processes, and services that Microsoft runs on—has created a standard engineering set of tools to identify where failures might occur and how to address them.
This approach is called Failure Mode Effective Analysis (FMEA). Microsoft uses FMEA to recognize potential failure risks, understand their impact, and mitigate them before they occur, rather than reacting after a failure occurs.
FMEA is combined with Service Quality Portal (SQP), a tool that combines Microsoft SharePoint, Microsoft Visio, and Microsoft Azure-based cloud applications. Built by an engineering team within Microsoft, it provides a full capability of risk management using the FMEA framework. SQP makes it much easier to track and mitigate the complex sets of failures that can occur in the cloud.
“It’s a matter of combining people, processes, and technology,” says Harsh Sharma, a senior program manager for Microsoft. “SQP and FMEA provide the framework we need to make our systems more secure and stable.”
[Learn how Microsoft created a telemetry platform to uncover information about end-to-end enterprise health with Microsoft Azure. Find out how Microsoft monitors SAP end to end on Microsoft Azure. Learn about how Microsoft has created a modern data-governance strategy.]
Once risks are identified, engineers can set up auto-detect to identify and mitigate failures, allowing them to replace the human decision-making used previously.
This new approach addresses how computing faults have evolved over the past 20 years.
Back then, an IT failure was invariably a local event, limited to a handful of PCs or an enterprise’s central servers. But today, with most computing taking place in the cloud, IT infrastructure is widely distributed. It’s also often built with commodity hardware that depends on an array of third-party and partner services.
“Cloud services are complex,” Sharma says. “They have a lot of moving pieces and need a lot of scalability. Owners of services may even have to rebuild their cloud architecture on occasion.”
Several years back, faults were outlined and tracked on a Microsoft Excel spreadsheet. Extrapolate this to more than 2,000 service components in Microsoft Digital, and that’s a lot of spreadsheets.
To get around this, engineers use the SQP tool and FMEA method to store and maintain architecture diagrams and perform risk management prior to every major release.
Some failures are minor—perhaps a set of users can’t sign into an app, or the app has limited functionality. Others are more serious, such as widespread outages that shut down critical services for multiple cloud customers, such as email or access to important data.
The causes of these failures can vary widely as well, from natural disasters such as hurricanes, to human error or hardware or software errors.
Today we just can’t be in firefighting mode all the time. We’re committed to 99.9 percent reliability—sometimes 99.999 percent. So, it’s a requirement to proactively identify potential failures.
– Harsh Sharma, senior program manager
A new way to manage failures
The old ways of managing failures simply don’t work any longer. And for good reason.
In the past, “failure management” meant listing every possible error imaginable in the aforementioned Microsoft Excel spreadsheet, with information about how to respond. It’s as if a fire department listed potential fire hazards in every house, then did nothing until the smoke alarms went off.
“Today we just can’t be in firefighting mode all the time,” Sharma says. “We’re committed to 99.9 percent reliability—sometimes 99.999 percent. So, it’s a requirement to proactively identify potential failures.”
That has meant a shift in what successful fault mitigation looks like.
Rather than focus on extending time between failures, Microsoft Digital’s goal is to reduce time to recover. Complex systems are prone to a wide range of failures, so the best strategy is to cope with them in a way that minimizes impact on customers.
That’s where FMEA comes in.
It prioritizes work in areas such as detection, mitigation, and recovery from failures—all factors in reducing the time needed to correct a failure. Using this approach, engineering teams think through potential reliability weaknesses and are prepared when failures occur, greatly reducing impact on users.
One big part of that is using the design phase of a new service or product to understand how it might fail.
“We want to identify potential problems and poke holes in the service before something is deployed in production,” Sharma says. “You want to understand the types of failures that could occur, how it would impact a business, and what could be the cause. And you want to have telemetry in place so that you can be alerted to a failure before a customer tells you about it.”
Not that doing so is easy.
Microsoft engineers working with FMEA principles need to diagram a myriad of dependencies, determine how much redundancy a particular system has or needs, and how different parts of a cloud service interact. Interestingly, hardware components such as disks, processors, and routers are not given substantial attention. Their potential faults are already well understood and relatively easy to trace and fix.
Moving into the cloud has pluses and minuses for managing failures.
The cloud certainly presents a more complicated IT picture than the days of centralized IT. But it also creates its own backup.
We’re getting in front of issues before they become a big deal. Now we’re able to have conversations based on identifying failure points where we want to invest in new designs.
– Dale Voth, site reliability engineering manager

“Moving into the cloud allows us to provide resiliency in a more expedient fashion,” says Dale Voth, a site reliability engineering (SRE) manager for Microsoft. “But it can add cost. Moving legacy systems into the cloud can be challenging, but provides an ecosystem with more reliability and resilience options.”
Voth says that when he began his current role three years ago, service outages were common. But by identifying weak points and improving reporting telemetry, major problems have been greatly reduced.
“We’re getting in front of issues before they become a big deal,” he says. “Now we’re able to have conversations based on identifying failure points where we want to invest in new designs.”
FMEA helps connect sellers and customers
Microsoft marketers have plenty of ways to connect with their customers. But they have to be careful—they don’t want to overwhelm customers, or ignore them. They want to connect with customers at the right time: When they’re ready to buy.
“Given the vast number of marketing assets where our customers engage with us, that’s a challenge,” says Saravanan Arumugam Subramani, a senior system engineer at Microsoft. “A failure here might mean a sales contact is lost, or a seller reaches out at an inopportune time.”
A systematic approach such as FMEA ensures service reliability.
FMEA helps identify failure points across the ecosystem, quantify the risk, and mitigate them with appropriate design. FMEA provides a framework for engineers to collaborate and critique design and solutions constructively, promoting a culture of learning and growing. It also helps identify where to set up the appropriate bells and whistles so Microsoft Digital can proactively detect imminent failures and not spam engineers with false alerts.
Failures happen. But with the right engineering approach, they happen less often and with reduced impact. MS Digital is working to ensure its customers have the apps and services they need when they need them.
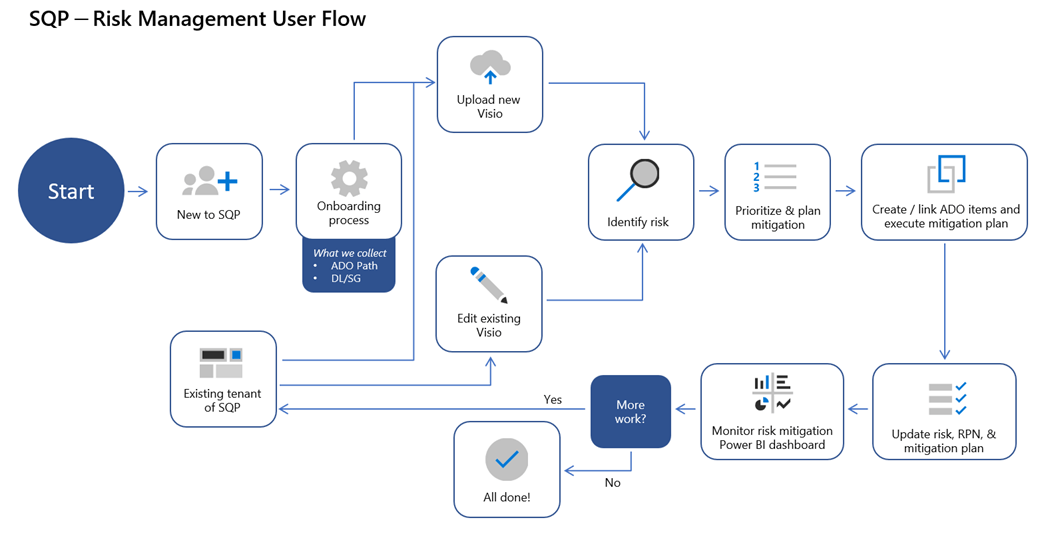
As MS Digital teams and Microsoft lean towards “shifting quality left” in the DevOps cycle, it’s becoming a necessity to identify potential risks in the design and architecture phase of DevOps and mitigate them prior to deploying in production.
As someone wisely said, “Prevention is better than cure.” Let’s practice it.
Find out how Microsoft monitors SAP end to end on Microsoft Azure.
Learn about how Microsoft has created a modern data-governance strategy.



