
The AI Infrastructure team at Microsoft Research India works on cutting-edge systems optimizations for improving the efficiency of a variety of AI/ML workloads, including an emerging class of workloads, namely, serving large language models (LLMs). AI/ML models are expensive to train and serve at scale and therefore, systems optimizations are crucial for unlocking the true potential of AI-powered applications. The key principle behind many of our projects is co-design of Systems and ML, i.e., we leverage deep domain knowledge of AI/ML workloads to design and improve the efficiency of these systems. Below is a summary of some of our current projects.
Etalon is a comprehensive performance evaluation framework that includes fluidity-index – a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Metron draws an analogy between periodic tasks in the rich literature of real-time systems and the streaming token generation in LLM inference and argues for a deadline-based evaluation of system performance rather than the conventional latency and throughput metrics. We have open-sourced Metron at https://github.com/project-etalon/etalon (opens in new tab), aiming to establish a standard for user-centric performance evaluation in the rapidly evolving landscape of LLM inference systems and frameworks.
vAttention is a dynamic KV cache memory allocator for serving Large Language Models. Compared to the popular PagedAttention model (pioneered by vLLM (opens in new tab)) that requires application-level changes, vAttention supports dynamic memory allocation transparently by leveraging low-level system support for demand paging. vAttention reduces software complexity while improving portability and performance. For example, vAttention unlocks the full potential of FlashAttention (opens in new tab)‘s and FlashInfer’s (opens in new tab) optimized kernels to significantly improve LLM serving throughput over vLLM.
VIDUR is a high-fidelity and extensible simulation framework for LLM inference. It models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance. It also includes a configuration search tool – Vidur-Search – that helps optimize LLM deployment. Vidur-Search automatically identifies the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 10s of thousands of GPU hours. Source available at https://github.com/microsoft/vidur (opens in new tab).
Just-in-Time Checkpointing Training Deep Neural Networks (DNNs) requires frequent checkpointing to mitigate the effect of failures. However, for large models, periodic checkpointing incurs significant steady state overhead, and during recovery, a large number of GPUs need to redo work since the last checkpoint. We present a novel approach of just-in-time checkpointing, which enables recovery from failures with just a single minibatch iteration of work replayed by all GPUs. This approach reduces the cost of error recovery from several minutes to a few seconds per GPU, with nearly zero steady state overhead.
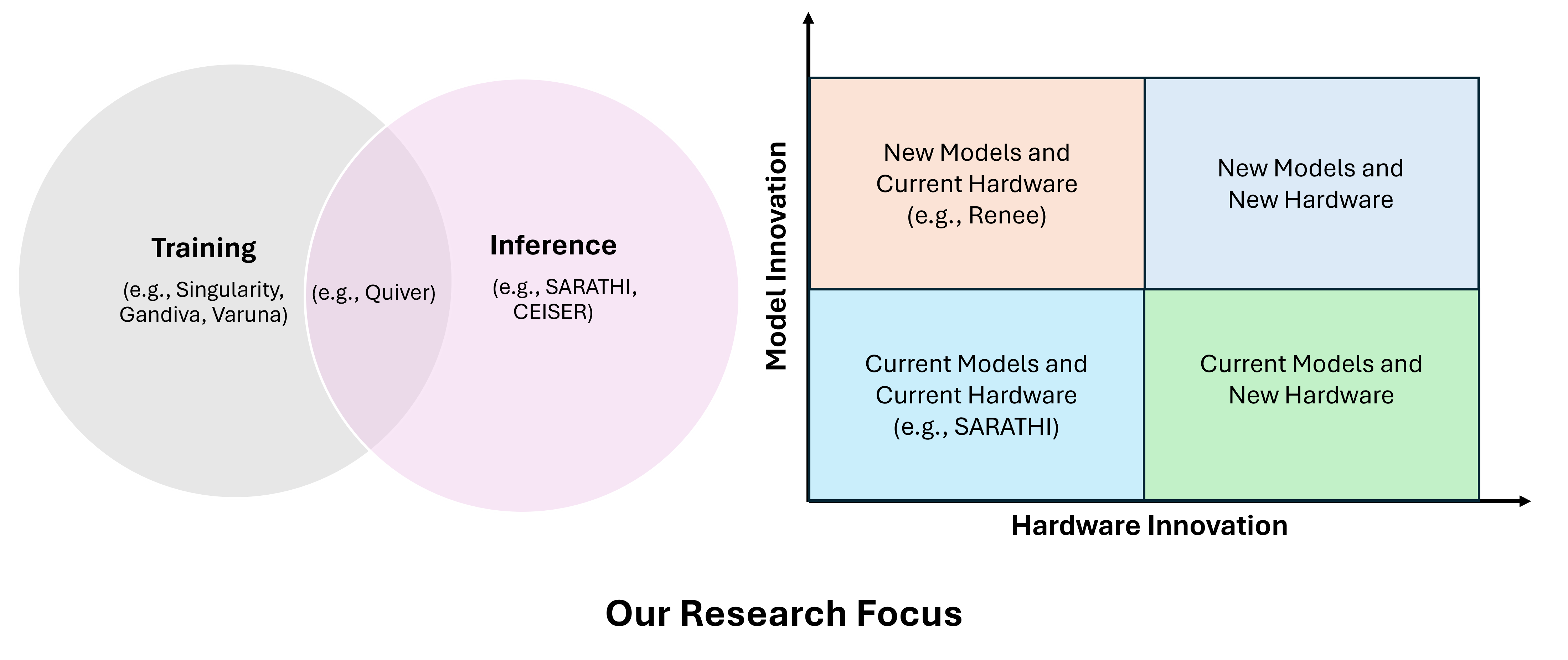
SARATHI is a technique to improve the throughput of LLM inference. Time to serve an LLM inference is dominated by the memory bandwidth on GPUs due to the auto-regressive nature of transformer-based architectures that generate one token at a time. We show that the decode cost per-token can be as high as 200 times the prefill (the initial phase wherein all the tokens of a query are processed in parallel) cost per token. Furthermore, the processing time of different batches can differ substantially due to varying number of tokens in different requests. This behavior introduces pipeline bubbles making it difficult to scale LLM inference on multiple nodes.
SARATHI addresses these challenges with two novel techniques: (1) chunked-prefills, which splits a prefill request into equal sized chunks, and (2) decode-maximal batching, which constructs a batch using a single prefill chunk and populates the remaining slots with decodes. During inference, the prefill chunk saturates GPU compute, while the decode requests ‘piggyback’ and cost up to an order of magnitude less compared to a decode-only batch. This approach allows constructing multiple decode-maximal batches from a single prefill request, maximizing coverage of decodes that can piggyback. Furthermore, the uniform work items of these batches ameliorate the imbalance between micro-batches, significantly reducing pipeline bubbles. Together, these optimizations substantially improve the decoding throughput of large language models across different models and GPUs.
CEISER takes an alternate approach to serving large classification models. State-of-the-art ML models for vision and language tasks promise ever-increasing accuracy, but deploying these large models for inference is often computationally expensive, with a prohibitive deployment cost. The usual mitigation is to distil the large model, i.e. decrease its size, and hence its computational cost for the specific task at hand, but this approach typically compromises inference accuracy. In CEISER (Cost Effective Inference SERving), we argue for an alternative to distilling large models: reducing inference cost, without compromising accuracy, by using ensembles of smaller models to achieve the desired overall accuracy. CEISER uses three techniques to achieve this. First, it introduces a novel ensemble selection algorithm that identifies the most cost-effective ensemble from the set of all possible ensembles for a given task using a bounded exploration strategy. Next, it determines the optimal compute-aware batch size that improves latency without compromising throughput. Finally, it performs input-aware scheduling of queries for tasks that are sensitive to the input distribution. Our experiments across different ML tasks and input loads on a physical cluster of 32 V100 GPUs and large-scale simulated clusters show that CEISER can reduce the monetary cost of inference serving by up to 50% compared to both the single largest model and prior work like Cocktail while providing the same accuracy as the best single model.
Renee is an end-to-end system for training Extreme Multi-label Classification (XC) models. The goal of XC is to learn representations that enable mapping input texts to the most relevant subset of labels selected from an extremely large label set, potentially in hundreds of millions. Given the extreme scale, conventional wisdom believes it is infeasible to train an XC model in an end-to-end manner. Thus, for training efficiency, several modular and sampling-based approaches to XC training have been proposed in the literature. In Renee, we identify challenges in the end-to-end training of XC models and devise novel optimizations that improve training speed over an order of magnitude, making end-to-end XC model training practical. Furthermore, we show that our end-to-end trained model, Renee´ delivers state-of-the-art accuracy in a wide variety of XC benchmark datasets.
Systems+ML co-design: The massive scale of cloud infrastructure services enables, and often necessitates, vertical co-design of the infrastructure stack by cloud providers. Our approach to co-design extracts efficiency out of existing software infrastructure layers by making lightweight changes to generic software interfaces. We explore co-design in the context of several systems: Singularity, Varuna, Gandiva and Quiver.
Singularity is a globally distributed scheduling service for highly efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs).
Varuna is a system that enables training massive deep learning models on commodity networking. Varuna makes thrifty use of networking resources and automatically configures the user’s training job to efficiently use any given set of resources. Therefore, Varuna is able to leverage “low-priority” VMs that cost about 5x cheaper than dedicated GPUs, thus significantly reducing the cost of training massive models.
Gandiva is a co-designed cluster scheduler for running deep learning training jobs. Gandiva leverages the predictability of DNN training jobs to make the scheduler “continuous” and “introspective”.
Quiver is an informed storage cache for deep learning jobs in a cluster of GPUs. Quiver employs domain-specific intelligence within the caching layer, to achieve much higher efficiency compared to a generic storage cache.